Aprendizaje por refuerzos con representaciones profundas para scheduling y planificación industrial
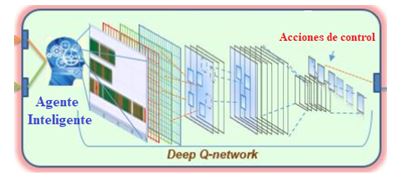 Contexto e Importancia – El escalado del aprendizaje por refuerzos a aplicaciones industriales como scheduling y planificación de cadenas de suministros que involucran numerosos productos, recursos y órdenes de producción y logística requiere representaciones relacionales de los distintos estados y las acciones posibles en cada uno de ellos para diferentes niveles de abstracción. Recientes avances en el aprendizaje automático de representaciones profundas usando redes neuronales (Deep Learning) permiten integrar el aprendizaje autónomo de representaciones con la búsqueda de una política óptima usando simulaciones y algoritmos de aprendizaje por refuerzos. En el plan de beca se abordará específicamente el uso específico de grafos para desarrollar un marco integrador de aprendizaje automático de representaciones neuronales relacionales especialmente diseñadas para describir restricciones de sincronización y precedencia en la solución de problemas de (re)scheduling y planificación automática.
Contexto e Importancia – El escalado del aprendizaje por refuerzos a aplicaciones industriales como scheduling y planificación de cadenas de suministros que involucran numerosos productos, recursos y órdenes de producción y logística requiere representaciones relacionales de los distintos estados y las acciones posibles en cada uno de ellos para diferentes niveles de abstracción. Recientes avances en el aprendizaje automático de representaciones profundas usando redes neuronales (Deep Learning) permiten integrar el aprendizaje autónomo de representaciones con la búsqueda de una política óptima usando simulaciones y algoritmos de aprendizaje por refuerzos. En el plan de beca se abordará específicamente el uso específico de grafos para desarrollar un marco integrador de aprendizaje automático de representaciones neuronales relacionales especialmente diseñadas para describir restricciones de sincronización y precedencia en la solución de problemas de (re)scheduling y planificación automática.
Problemática – Dos cuestiones centrales a abordar durante el escalado del aprendizaje por refuerzos a aplicaciones industriales son: i) el empleo de la optimización Bayesiana en el establecimiento automático de los distintos híper-parámetros, y ii) el desarrollo de representaciones profundas de tipo relacional que permitan describir las interacciones entre las líneas de producción y los distintos productos/órdenes con los recursos, tareas y sus correspondientes atributos y condicionamientos.
Objetivo – El objetivo prioritario del plan de beca es el desarrollo de un nuevo paradigma de diseño y programación de sistemas súper-inteligentes para rescheduling y planificación automática de procesos de producción y cadenas de suministros. El plan de beca se focalizará en el desarrollo de algoritmos autónomos de aprendizaje por refuerzos con representaciones profundas relacionales que integran optimización Bayesiana usando grafos y el empleo de procesos Gaussianos sobre tales grafos para la elección de los híper-parámetros de la política de control y la generalización de la misma a situaciones con números variables de tareas, recursos y órdenes.
Contacto: Dr. Ernesto C. Martínez (ra.vo1784153195g.tec1784153195inoc-1784153195efatn1784153195as@ra1784153195gnIsa1784153195ceb1784153195)