Selección Autónoma de Hiper-Parámetros en Algoritmos para Aprendizaje por Refuerzos
Contexto e Importancia – En las últimas dos décadas, el uso de métodos de aprendizaje por refuerzos ha experimentado un crecimiento exponencial y usando este enfoque se han podido entrenar agentes inteligentes capaces de llevar a cabo una diversidad de tareas complejas de control u optimización tales como manipular robots, conducción autónoma, planificar experimentos para testear hipótesis o realizar recomendaciones en dominios tan variados como la salud, optimizar en tiempo real Smart Grids o derrotar a grandes maestros en juegos como Go o StarCraft. Sin embargo, para transformar la experiencia de secuencias de interacciones en un comportamiento aceptable del agente, el costo del aprendizaje y la performance del comportamiento resultante presentan una enorme dependencia de los hiper-parámetros de los algoritmos implementados, lo que incluye no solo en el contenido informativo de los datos generados en las interacciones entre el agente y el entorno, sino también el mismo algoritmo usado para aprender o la forma de representación de los estados y acciones.
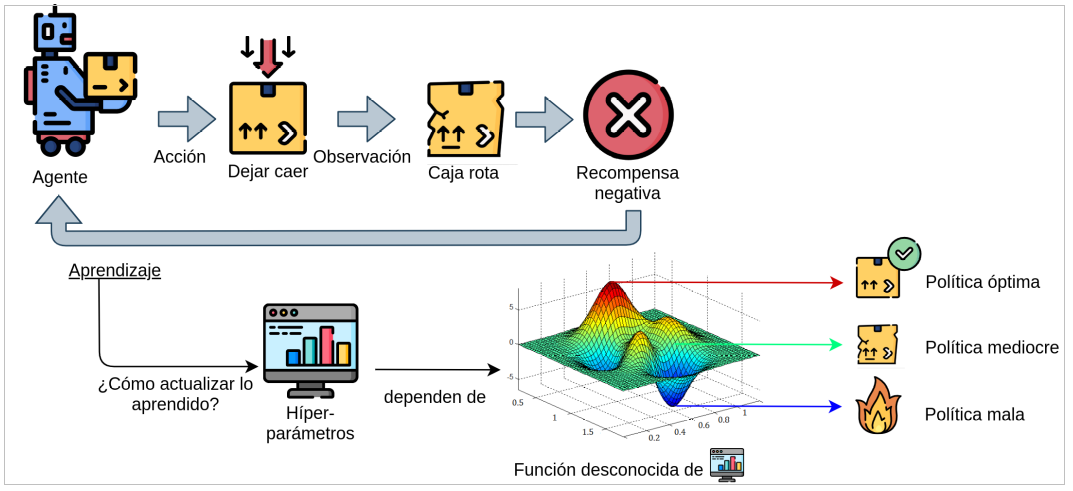
Aprendizaje por refuerzo
Problemática – A falta de un mecanismo de selección autónoma de todo el conjunto de hiper-parámetros necesarios, la practica usual consiste en elegirlos por prueba y error, lo que demanda una enorme cantidad de interacciones entre el agente con su entorno y, por lo tanto, dilapidar una significativa cantidad de recursos computacionales y costosos experimentos en una lenta curva de aprendizaje caracterizada por un pobre balance entre explotar el conocimiento adquirido o explorar para adquirir más conocimiento relevante. Por tanto, la adecuada elección de todos los hiper-parámetros (que incluyen variables enteras, categóricas y reales) es determinante ya que dependiendo de ellos se podrá alcanzar un desempeño próximo al optimo o uno mediocre, incluso la imposibilidad de entrenar satisfactoriamente al agente. La selección o tuning automático de los hiper-parámetros es por tanto imprescindible para acelerar la curva de aprendizaje del agente e independizar al usuario de conocimiento profundo acerca de los métodos utilizados.
Objetivo – El plan de la beca se focaliza en el diseño y prueba computacional exhaustiva de algoritmos autónomos de aprendizaje por refuerzos utilizando técnicas de optimización Bayesiana para la selección autónoma de los hiper-parámetros. Especial atención se dedicará a tareas complejas de control donde se utilizan representaciones profundas para codificar el comportamiento optimo del agente. Como casos de estudio se abordarán problemas asociados con rescheduling de tareas en tiempo real y negociación automatizada entre agentes en un mercado peer-to-peer de prosumidores energéticos.
Contacto:
Dr. Ernesto C. Martínez (ra.vo1785021448g.tec1785021448inoc-1785021448efatn1785021448as@it1785021448ramce1785021448)
Dr. Carlos Fischer (ra.vo1785021448g.tec1785021448inoc-1785021448efatn1785021448as@re1785021448hcsif1785021448c1785021448)